Sentimen Analisis Twitter Menggunakan R Programming
/
0 Comments
Sentimen Analisis Twitter Menggunakan R programming
Kelompok
- Emirza mahendara
- Fajar Sukma
- Krisna Mustikarani
- Ruth Inggrid Sitompul
Pada artikel kali ini, akan dibahas mengenai cara menganalisa sentimen masyarakat melalui media sosial Twitter terhadap bullying menggunakan aplikasi R. Berikut ini adalah hal-hal yang harus disiapkan:
- Install Software R, anda dapat mengunduhnya disini. Usahakan menggunakan software R versi terbaru, versi saat ini yang terbaru adalah 3.4.4
- Buat API Key dan Acces Token dari Twitter. Caranya dengan membuat akun pada Twitter Apps.
- Kunjungi https://apps.twitter.com dan Login menggunakan akun Twitter yang anda miliki, agar selanjutnya dapat membuat akun pada Twitter Apps.
- Kemudian Create New App.


- Ceklis pada Developer Agreement.
- Kemudian klik “Create your Twitter Application” .
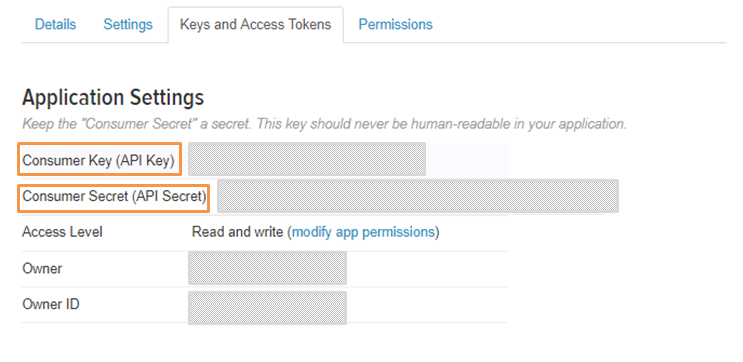
- Setelah akun terbuat, masuk pada jendela “Keys and Access Tokens”. Dapat dilihat bahwa kita sudah memiliki Consumer Key (API key) dan Consumer Secret (API secret). Tetapi belum memilik Token, untuk mendapatkan Token, bisa dengan klik “Create my access token” yang berada pada bagian bawah.

 S
S
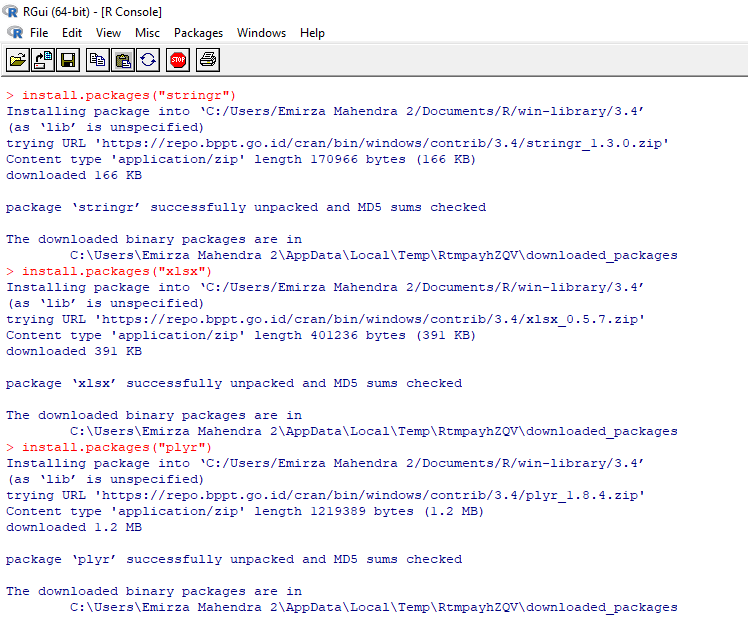
Setelah itu lakukan installasi packages yang dibutuhkan. Pada saat menginstall packages twitteR, nantinya akan muncul Secure CRAN mirrors, pilih Indonesia(Jakarta)[https]


# Install R packages required
install.packages("twitteR")
install.packages("stringr")
install.packages("xlsx")
install.packages("plyr")
# Load the required R libraries
library(twitteR)
library(stringr)
library(xlsx)
library(plyr)
Penginstallan packages tambahan R digunakan sintaks install.packages disertai dengan sintaks library (nama_package). Packages yang ditambahkan dalam sentiment analysis pada Twitter adalah:twitteR
Package ini yang akan membantu dalam pengaksesan ke API Twitter, sehingga memungkinkan crawling atau pengambilan data pada Twitter.

Ketika fungsi dijalankan setup_twitter_oauth(), R console akan menanyakan: “Use a local file to cache OAuth access credentials between R sessions?”. Masukkan angka “2” yang berarti No.
- String
- Xlsx
- Rcurl
- ROAuth
- Base64enc
Selanjutnya masukan API yang sudah didapatkan sebelumnya, dengan syntax berikut:
consumerKey <- " kcvzlbxxxxxxxxxxxxxxxxxxxxxxx"
consumerSecret <- " VLcNdxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
accessToken <- " 1329527xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
accessTokenSecret <- " i0qfY9Ek95xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
setup_twitter_oauth(consumerKey, consumerSecret, accessToken, accessTokenSecret)
Jika sudah berhasil, artinya kita sudah terkoneksi pada Twitter API dan R siap untuk mengambil data. Maka, untuk menguji apakah kita sudah dapat melakukan crawling pada tweet dengan suatu keywoard, kita dapat melakukan percobaan mendapatkan tweet dengan cara seperti dibawah ini, yang akan menghasilkan 25 tweet yang merupakan default dari pengambilan tweet dalam R.
Disini terdapat bank kata berupa file text yaitu text yang berisikan kata-kata bermuatan positif dan juga kata-kata yang bermuatan negatif, bank kata ini tersimpan ke dalam file positive-word.txt dan negative-word.txt.

Saat melakukan crawling, beberapa tweet akan mengandung angka, tanda baca, atau huruf besar , hal-hal demikian harus dibersihkan, agar data yang diperoleh hanyalah berupa string yang bersih, maka selanjutnya kita membuat fungsi sentiment yang terdiri dari beberapa parameter yaitu untuk membersihkan tweets yang akan diambil nantinya, dan variabel positif dan negatif yang sudah di deklarasikan sebelumnya.
Merupkan fungsi perhitungan score yang nantinya akan menjumlahkan tweets positive dan tweets negative, untuk sebuah kata positive bernilai +1 dan sebuah kata negative bernilai -1, sedangkan kata yang normal bernilai .

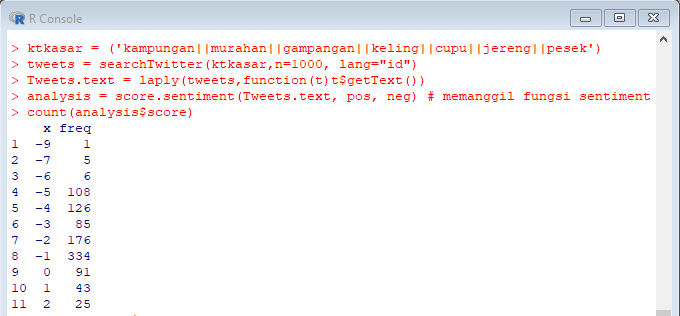
Dapat dilihat pada gambar di atas bahwa rentang nilai sentimen dari -9 sampai 2 dengan jumlah terbanyak berada di nilai -5, -4, -2 dan -1 dengan rincian tweet negatif sebanyak 841 tweet, netral sebanyak 91 tweet dan positif sebanyak 68 tweet. Dari data tersebut terlihat bahwa 84,1% kata mengandung Bullying di Twitter dengan menggunakan kata kampungan, murahan, gampangan, keeling, cupu, jereng, pesek.
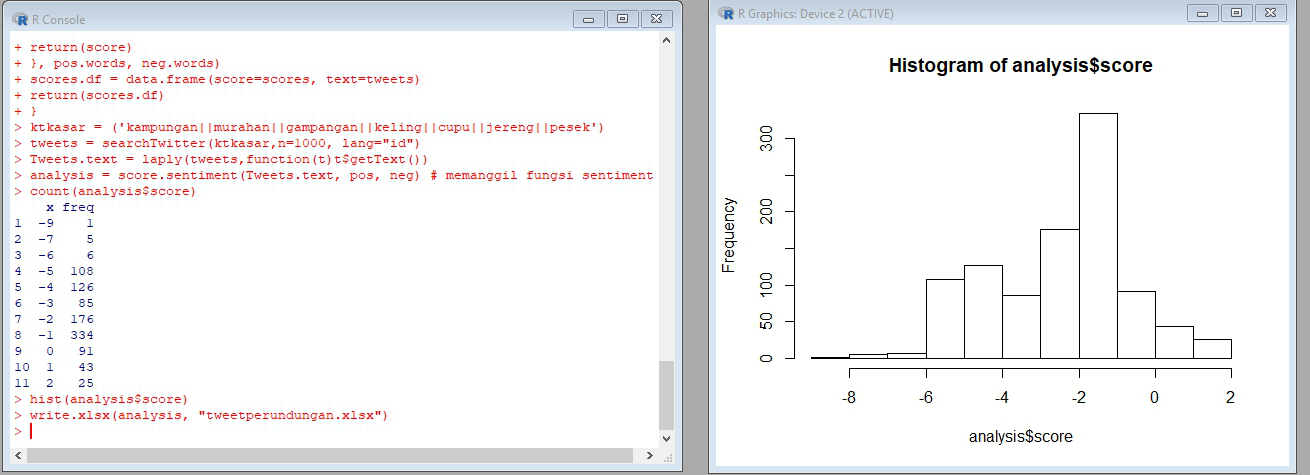
Untuk memindahkan hasil ke dalam bentuk excel dengan menggunakan library xlsx dan menyimpannya ke file excel bernama tweetperundungan.xlsx.

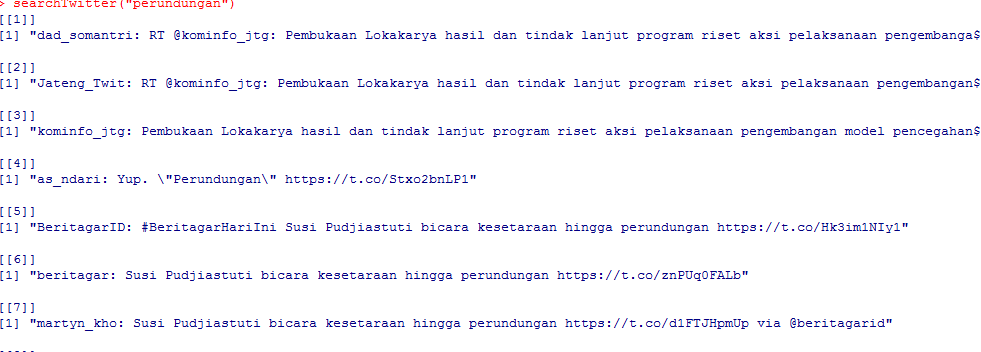
Berikut adalah hasil data yang terdapat pada Excel

searchTwitter("perundungan")
Selanjutnya adalah memindai kata-kata Positive dan Negative dengan membuat bank kata yang berisi kata-kata Positivedan Negative secara lengkap, makin lengkap bank kata yang kita miliki, maka akan semakin akurat juga analisis yang kita dapatkan.
Kita akan membaca file tersebut dengan fungsi scan pada R, dan menyimpannya kedalam variabel ‘pos’ untuk kata positif, dan ‘neg’ untuk kata negatif. Dengan cara mengetikkan sintaks dibawah ini.

Kita juga dapat menambah berbagai kata baru pada variabel pos, atau neg yang sudah kita dekklarasikan, dengan menggunakan fungsi combine c(), misal kita ingin menambahkan kata negatif baru maka kita dapat mengetikkan sintaks berikut, maka kata akan tergabung dengan variabel neg.
pos = scan('D:/Fajar/Belajar Pemrograman/R Programming/positive-words.txt', what='character')
neg = scan('D:/Fajar/Belajar Pemrograman/R Programming/negative-words.txt', what='character')
neg = c(neg,'murahan','gampangan','idiot','najis', 'goblok')
score.sentiment = function(tweets, pos.words, neg.words){
require(plyr)
require(stringr)
scores = laply(tweets, function(tweet, pos.words, neg.words) {
Syntax dibawah ini berguna untuk mebersihkan tweet dengan fungsi gsub()
tweet = gsub('https://','',tweet)
Syntax untuk menghapus https://
tweet = gsub('http://','',tweet)
Syntax untuk menghapus http://
tweet=gsub('[^[:graph:]]', ' ',tweet)
Syntax untuk menghapus karakter grafik
tweet = gsub('[[:punct:]]', '', tweet)
Syntax untuk menghapus tanda baca
tweet = gsub('[[:cntrl:]]', '', tweet)
Syntax untuk menghapus karakter control
tweet = gsub('\\d+', '', tweet)
Syntax untuk menghapus digit/angka
tweet = str_replace_all(tweet,"[^[:graph:]]", " ")
tweet = tolower(tweet)
Syntax untuk mengubah huruf besar menjadi huruf kecil
word.list = str_split(tweet, '\\s+')
Syntax untuk memecah tweet perkata kedalam sebuah list
words = unlist(word.list)
Syntax untuk mengubah list kedalam vektor
pos.matches = match(words, pos.words)
neg.matches = match(words, neg.words)
Syntax untuk membandingkan katakata dengan bank kata negative dan positive yang sudah dibuat sebelumnya.
pos.matches = !is.na(pos.matches)
neg.matches = !is.na(neg.matches)
Syntax untuk mengubah kata yang cocok kedalam bentuk TRUE ata
score = sum(pos.matches) - sum(neg.matches)
return(score)
}, pos.words, neg.words)
scores.df = data.frame(score=scores, text=tweets)
return(scores.df)
}
Syntax TRUE/FALSE akan dianggap sebagai 1/0 sehingga dapat ditambahkan dengan fungsi sum() :
Dan berikut adalah perintah untuk mencari kata-kata bersifat bullying
ktkasar = ('kampungan||murahan||gampangan||keling||cupu||jereng||pesek')
tweets = searchTwitter(ktkasar,n=1000, lang="id")
Tweets.text = laply(tweets,function(t)t$getText())
analysis = score.sentiment(Tweets.text, pos, neg)
- ktkasar , merupakan kata kunci yang digunakan untuk mengambil tweet tweet, sehingga tweet yang mengandung kata kata tersebut akan diambil.
- searchTweet, merupakan fungsi untuk mengambil tweet melalui twitter API, dimana paramaeter yang diberikan disini adalah variabel ktkasar, dan n adalah jumlah tweet yang akan diambil yaitu sebanyak 1000 tweet.
- Fungsi laply berfungsi untuk mengambil text tweet
- Fungsi score sentiment, merupakan fungsi yang sudah dibuat sebelumnya untuk melakukan analisis sentiment terhadap tweet yang sudah diambil.
count(analysis$score)
Fungsi count() untuk menghitung banyak frekuensi nilai sentimen.
Untuk menampilkan hasil dalam bentuk histogram berdasarkan data yang diperoleh, dapat dilakukan dengan memasukan syntax dibawah ini;
hist(analysis$score)






.png)